Hint: It's Not Real Intelligence. Part 1 of The Enterprise AI Investment Series: a framework for executives making AI investment decisions in 2026.

You are here:
Your AI investment strategy will fail if your mental model of AI is wrong.
That's not a criticism. It's a structural problem. Most executives making AI decisions today were handed a mental model built from two sources: vendor demos and media headlines. Neither source had any incentive to be accurate.
The result? Enterprises consistently mis-calibrate. They over-restrict harmless internal pilots. They under-govern risky production deployments. They invest in the wrong layer. They measure the wrong outcomes. And then, twelve months in, they're part of the 95%: the share of enterprise GenAI initiatives that MIT Media Lab's Project NANDA found had delivered no measurable P&L impact (The GenAI Divide, Challapally et al., 2025). McKinsey's 2025 State of AI report tells a consistent story: only 39% of organisations report EBIT impact from AI at the enterprise level, and just 6% qualify as "high performers."
The mental model is the problem. Fix that first. Everything else in this series depends on it.
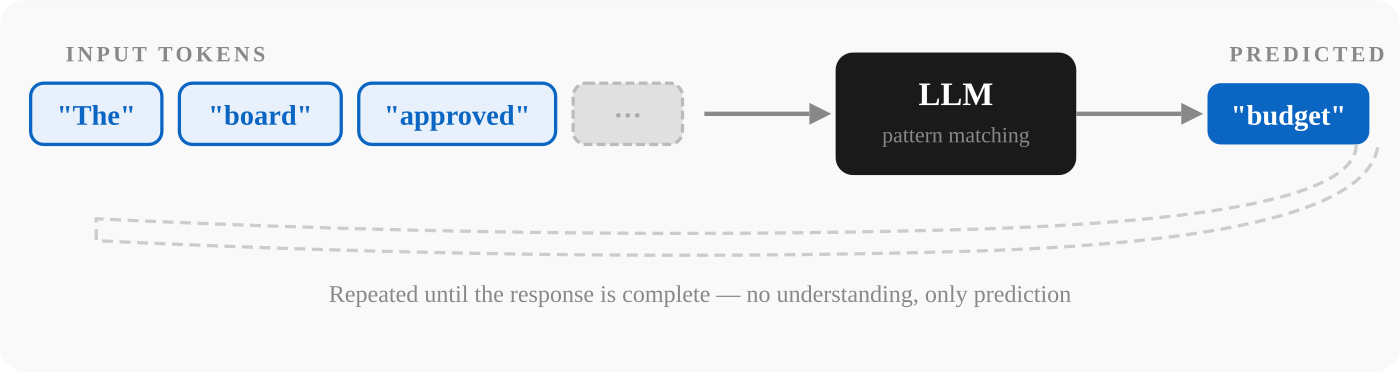
An LLM predicts the most probable next word based on what came before. Brilliantly, but mechanically.
A Large Language Model does one thing: it looks at the words that came before and predicts the statistically most likely next word. Then it does it again. And again. Until the response is complete.
That's it.
The output sounds intelligent because the training data (most of the written internet) contains enormous amounts of human thought, explanation, and reasoning. The model has learned, at extraordinary scale and resolution, what good answers tend to look like. It can produce fluent, structured, persuasive text on almost any topic.
But it is not reasoning or understanding. It has no knowledge base to consult. It is pattern-matching at a scale that mimics intelligence without possessing it.
I use the phrase next-word guesser deliberately. Not to diminish the technology (it's genuinely remarkable) but because the word "intelligence" in "artificial intelligence" has caused more enterprise failures than any technical limitation. When executives believe they are deploying something that understands their business, they govern it like something that understands their business. That's how a hallucination becomes a regulatory incident.
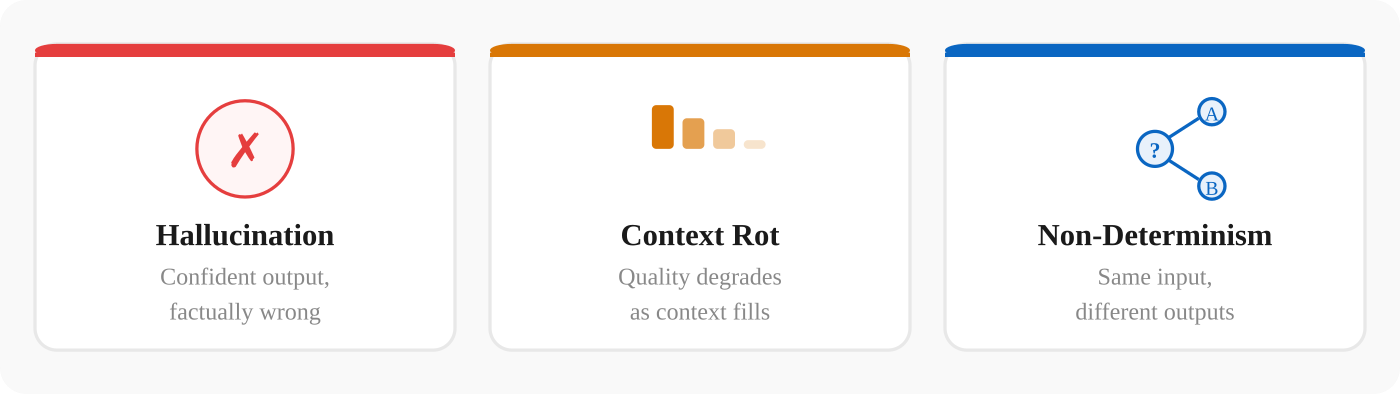
These are not bugs to be fixed. They are structural features of how the technology works.
The architecture that makes LLMs powerful also gives them three properties that don't disappear with better models or bigger context windows. These are not bugs. They are features of how the technology works.
1. Hallucination
An LLM will generate confident, fluent, plausible-sounding text that is factually wrong. Not occasionally. Structurally. Because the model's job is to produce likely-looking output, not truthful output. It has no mechanism to verify what it says against external reality.
As Yann LeCun, formerly Meta's chief AI scientist and now founder of AMI Labs, has argued repeatedly, autoregressive LLMs lack a world model. They generate plausible text without grounding it in factual reality. The architecture produces fluency, not truth.
In a regulated industry, hallucination looks like this: a model cites a regulation that doesn't exist, an account detail that was never recorded, or a legal precedent that was invented. The output is grammatically perfect and tonally confident. No warning label.
This is not a problem that prompt engineering fixes. It's not a problem that a better model eliminates. It is a risk that responsible architecture manages. The distinction matters for governance decisions.
2. Context Rot
Every LLM operates within a context window, the amount of text it can "see" at once. When that window fills up, older information gets compressed or dropped. Quality degrades as the window fills, and the model grows less reliable precisely when you're asking it to synthesise the most information.
Stanford researchers documented this as the "lost in the middle" phenomenon (Liu et al., Transactions of the Association for Computational Linguistics, 2024): critical information buried in the middle of a long document is frequently missed, even when the model technically has the context capacity to process it.
Bigger context windows help at the margins. They don't solve the problem. An enterprise that tries to compensate for weak architecture by "just adding more context" is building on unstable ground.
3. Non-Determinism
Classical enterprise software is deterministic. Given the same input, it produces the same output. Every time. That predictability is the foundation of auditability, testing, and trust.
LLMs are probabilistic. Give the same model the same prompt twice, and you will get different outputs. Sometimes subtly different. Sometimes substantively different.
This is not a calibration problem. It is a property of how the models generate text. For any enterprise process that requires reproducibility (compliance documentation, audit trails, regulated decisions), this is not an edge case. It is the central engineering challenge.
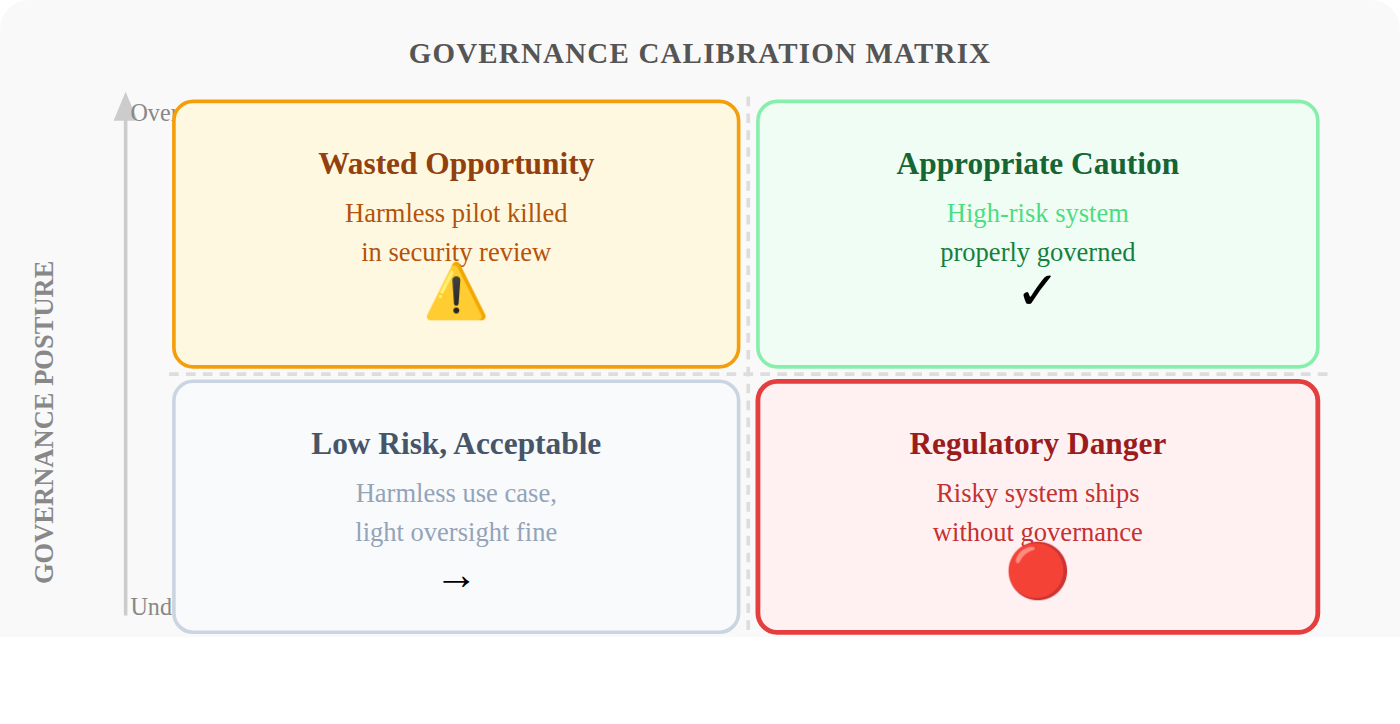
Most enterprises land in the two wrong quadrants: over-restricting harmless tools while under-governing risky ones.
The same pattern repeats across enterprise AI programs.
The team with the conservative risk manager bans LLMs from internal tools. Their legal department is worried about data leaving the building. The use case: a knowledge assistant that helps employees find the right internal policy document. Zero customer data involved. Zero regulated decision. The pilot dies in security review.
Meanwhile, in the same organisation, a different team ships a customer-facing credit recommendation tool with minimal governance. It's fast-moving, gets executive sponsorship, goes to production. Three months later, it produces a recommendation that regulators would describe as unexplainable.
In APAC financial services, regulators are increasingly specific about this: MAS's FEAT principles (Singapore) and the Bank of Thailand's 2025 AI Risk Management Guidelines both require explainability for consequential automated decisions.
When you think AI is either "magic" or "dangerous," you make binary decisions. Both responses are wrong. Both are expensive.
The right framework is not approve or block. It's assess the actual risk of this specific deployment and govern proportionally. That framework requires the mental model we're building in this article.
Classical software behaves the same way every time you run it. You can test, certify, and audit it. You can write a test suite that covers its behaviour, and if all tests pass, you have reasonable confidence in the system.
AI systems don't work like this.
When you deploy an LLM-powered system, you are not deploying a piece of software. You are deploying a probabilistic process that will produce a distribution of outputs across a distribution of inputs. The system's behaviour is characterised by that distribution, not by any single execution.
This changes how you test, how you monitor, how you define "working correctly," and how you staff the team that maintains it. Most enterprise organisations have not caught up to this shift. They inherited quality assurance practices from thirty years of deterministic software and are applying them to a fundamentally different class of system.
The leaders who understand this shift will build AI programs that survive contact with production. The leaders who don't will spend 2026 and 2027 trying to explain to their boards why the pilot that looked so promising in the demo keeps generating unexpected outputs in the real world.
Most enterprise software projects have a clear definition of "done." Acceptance criteria. User stories. Test scripts. The UAT phase exists to verify that the system does what the business said it should do.
Most AI projects fail UAT, or skip it entirely, because nobody defined what "good" looks like for a probabilistic system.
If your CRM system processes a customer update correctly 100% of the time, it passes testing. If your AI system produces the right answer 87% of the time: is that a pass or a fail? For what use case? With what threshold? Measured how, on whose test data?
Gartner predicted in July 2024 that at least 30% of GenAI projects would be abandoned after proof of concept by end of 2025. By April 2026, the observed rate had climbed to 50%. Projects that looked great in the pilot (where success criteria were vague and the demo was curated) collapse when someone tries to measure real-world performance at scale.
This is not a technical problem. It is a product management and governance problem that happens to sit in a technical context. The organisations that solve it early will deploy AI systems that compound in value. The organisations that don't will fund an endless cycle of pilots that never reach production.
The rest of this series is about investment decisions: where to put money, how to think about AGI timelines, how to build governance, how to make AI infrastructure that survives the next model generation.
None of those decisions make sense without this foundation.
If you think LLMs reason, you will make different architecture choices than if you know they predict. If you think hallucination is a prompt engineering problem, you will under-invest in retrieval and verification systems. If you think non-determinism is a temporary limitation, you will defer the organisational change that comes from operating probabilistic systems at scale.
AGI timelines, which we'll cover in Part 3, raise the stakes further, not lower them. If the capability of these systems is going to increase substantially over the next few years, the organisations with the right mental model now will compound those gains. The organisations without it will keep starting from scratch.
Start here. Get this right. The investment decisions follow.
Now that you understand what AI is and isn't, Part 2 covers the three places you can actually put money, and which layer most enterprises are ignoring.
Thunyut "Fang" Chienpairoj is a Bangkok-based builder, AI practitioner, and enterprise AI lead at a global consulting firm with 15+ years shipping technology across startups, corporates, and global consulting. He is the rare kind of technologist who can write the code, design the product, and lead the boardroom conversation, and he does all three at the frontier of AI. Follow on LinkedIn for the rest of this series.